Does the type of container used to hold strings affect the speed of string equality comparisons?
Introduction
Comparing two string objects to determine equality is a common operation within computer programming. In this post, we will perform a series of experiments to discover if different containers influence the speed of equality comparisons, specifically comparing a value against all of the values within the container. We will the review the experimental results to arrive at an empirical conclusion about the impact of container types on string equality comparison operations.
Motivation
Given the prevalence of comparison operations within computer programming, especially comparisons where a given value is being compared against values in a container, we felt that the processing speed implications of different container types would be a beneficial data point for computer programmers to have as they made implementation decisions throughout their work. When deciding on a specific architecture, having clear data about container types’ impact on equality checking would provide beneficial information to help in container type selection.
Method
Approach
At the core of our experiment is comparison logic. We need to compare a string against the string values in a collection. This is accomplished by using a for loop, as demonstrated in the code block below.
# Function to perform equality comparisons between a passed value and values in the container
def compare_value_in_container(
value: str, container: (list | set | dict)
) -> list:
"""
Compare the passed value with each element in the container.
"""
# Depending on the type of container, loop through and compare values
# For lists and sets, compare directly to each element
if isinstance(container, (list, set)):
return [value == item for item in container]
# For dictionaries, compare the value against each key-value pair
if isinstance(container, dict):
return [value == entry for entry in container.values()]
# Container type is unsupported by this toolset
raise TypeError("Unsupported container type")The logic runs an inline for loop, comparing the passed-in string value against each of the values within the passed-in container of string values. In an effort to keep our research focused, we solely utilized str type values within our processing.
In order to limit our time measurements specifically to the comparison operations, we’ve architected our code to record the time for the comparison, but to ignore any time utilized to create the collections being analyzed.
# Perform the containment check benchmark
def perform_containment_check_benchmark(
value: str,
# The value to compare against elements in the container.
container: (list | set | dict),
# The container holding the elements to compare against.
number_runs: int = 10,
# The number of runs per benchmark.
number_repeats: int = 3,
# The number of times to repeat the benchmark.
) -> List[float]:
"""
Run an experiment using the timeit package for the specific function.
This function benchmarks the comparison of a value against elements in a container
using the `benchmark_comparison` function. It runs the comparison `number_runs` times
per benchmark and repeats the benchmark `number_repeats` times to get a reliable measurement.
Args:
value (str): The value to compare against elements in the container.
container (list | set | dict): The container holding the elements to compare against.
number_runs (int): The number of runs per benchmark.
number_repeats (int): The number of times to repeat the benchmark.
"""
times = timeit.repeat(
# Perform the benchmark using the `benchmark_comparison` function
lambda: comparison_logic.compare_value_in_container(value, container),
number=number_runs,
repeat=number_repeats,
)
return timesThe value to search for, and the container, are both passed in as parameters to this function, which uses the timeit module to run multiple instance of the logic and then report out results.
Raw Data
| Container Type | String Length | Container Size | Min Time | Avg Time | Max Time |
|---|---|---|---|---|---|
| Set | 100 | 100,000 | 0.073553 |
0.073723 |
0.073947 |
| List | 100 | 100,000 | 0.018447 |
0.018741 |
0.019304 |
| Dictionary | 100 | 100,000 | 0.021495 |
0.022215 |
0.023176 |
| Set | 100 | 50,000 | 0.015568 |
0.016286 |
0.017164 |
| List | 100 | 50,000 | 0.008816 |
0.009133 |
0.009390 |
| Dictionary | 100 | 50,000 | 0.010052 |
0.010084 |
0.010136 |
| Set | 100 | 25,000 | 0.007795 |
0.009405 |
0.011840 |
| List | 100 | 25,000 | 0.004432 |
0.004523 |
0.004619 |
| Dictionary | 100 | 25,000 | 0.004996 |
0.005133 |
0.005233 |
| Set | 200 | 100,000 | 0.102771 |
0.105011 |
0.107937 |
| List | 200 | 100,000 | 0.027504 |
0.028650 |
0.029245 |
| Dictionary | 200 | 100,000 | 0.030532 |
0.032309 |
0.033476 |
| Set | 200 | 50,000 | 0.042385 |
0.047238 |
0.051337 |
| List | 200 | 50,000 | 0.010158 |
0.010570 |
0.011372 |
| Dictionary | 200 | 50,000 | 0.014681 |
0.015522 |
0.016787 |
| Set | 200 | 25,000 | 0.008394 |
0.008806 |
0.009481 |
| List | 200 | 25,000 | 0.004929 |
0.006933 |
0.009785 |
| Dictionary | 200 | 25,000 | 0.005190 |
0.005400 |
0.005553 |
| Set | 400 | 100,000 | 0.107843 |
0.109054 |
0.110224 |
| List | 400 | 100,000 | 0.038784 |
0.039341 |
0.039654 |
| Dictionary | 400 | 100,000 | 0.044132 |
0.045181 |
0.046891 |
| Set | 400 | 50,000 | 0.032686 |
0.034432 |
0.035384 |
| List | 400 | 50,000 | 0.012241 |
0.013212 |
0.014575 |
| Dictionary | 400 | 50,000 | 0.014732 |
0.017525 |
0.019509 |
| Set | 400 | 25,000 | 0.008965 |
0.009877 |
0.011552 |
| List | 400 | 25,000 | 0.005139 |
0.005639 |
0.006630 |
| Dictionary | 400 | 25,000 | 0.005534 |
0.006304 |
0.007326 |
Charts
The following charts show clearly that evaluating within a Set takes additional time. In some cases, nearly three times as much as the shortest container type. At the same time, the data shows that there is a very minimal difference between the List and Dictionary container types when considering string equality comparisons.
Data for Long Strings
This is a chart using the subset of the Raw Data above where the String Length is 400. The “Avg Time” value is then aggregated per Container Type.
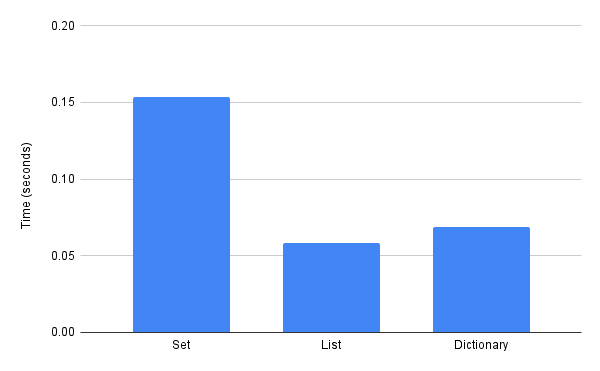
Data for Large Containers
This is a chart using the subset of the Raw Data above where the Container Size is 100,000. The “Avg Time” value is then aggregated per Container Type.
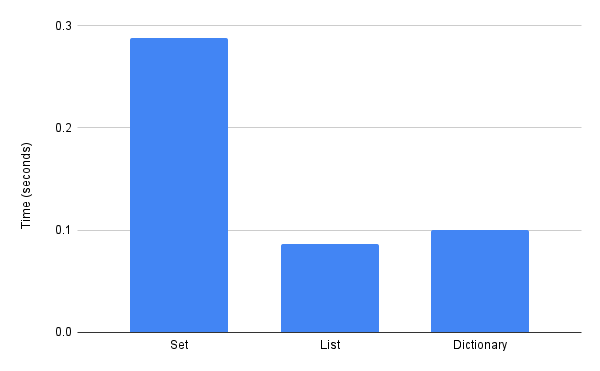
Results
The data presented here demonstrate that performing string equality comparisons using a Set is notably slower than the same comparison operations on either List or Dictionary. When considering similar container sizes and object sizes within the containers, we see a significant speed penalty for using a Set. In at least one comparison, the ‘Long List of Short Strings’ experiment, we see that using a List required on average one quarter the time necessary to perform the same operations in a Set. This would align with the underlying processing infrastructure of Python. Within Python, the Set data structure is optimized for containment checking; that same optimization limits the performance speed of looping through the contents of a Set especially when compared against the sequential memory storage setup of List structures.
In nearly every experiment we found that a List performed faster than the Dictionary, in fact only one of our experiments showed a Dictionary faster than a List. The difference between the average elapsed time for these two container types varied with List being between 9.43% to 31.90% faster in cases where it was faster. The one case where Dictionary was faster than List showed a 28.39% speed benefit when using Dictionary. This data seems inconclusive, given it’s wide range and lack of clear conclusion. At most, the data show that List would typically provide a faster performance than Dictionary, but individual use-cases should be evaluated to determine the best container in specific applications.
Next Steps
Given the inability to draw any conclusions about the relative benefits of Dictionary and List containers, we recommend that further experiments be run in order to specifically analyze the performance of these two container types against each other. While we have not taken the time necessary to establish a detailed experimental design, we would recommend focusing on these two container types and utilizing larger data sets for each experiment with a larger number of runs in each experiment. The theory we posit is that with additional experimental outputs, from larger datasets, the outputs would be more stable and at a timing resolution that is possible to evaluate.
References
These references were utilized during the creation of the experimental harness used to generate the empirical data referenced in this write-up.
- https://stackoverflow.com/questions/48510512/python-comparing-value-to-an-element-of-list-of-lists/
- https://stackoverflow.com/questions/3860009/custom-comparison-for-built-in-containers/
- ChatGPT : Used for information about the comparison of a value against elements in a container and also the use of
isInstance()to check the type of container. - Copilot
- Used for debugging the code with ‘Fix with Copilot’.
- Used to generate the function signature type annotations in order to meet the class expectations.
- Grammarly: an AI assistant that helps me with spelling and grammar errors. Used in comments.
- educative: Used to understand the module utilized to generate random strings, specifically
import string;. - https://stackoverflow.com/questions/25272400/which-one-is-faster-iterating-over-a-set-and-iterating-over-a-list/