When creating functions that involve integer computation it is important to consider different implementations that result in the same integer output. Different implementations may result in different run times. In this, we investigate two different implementations of the sum_stop_int function and how the changes in code impact the performance.
Function Explanation
The function sum_stop_int is meant to calculate the sum of all numbers up to the given stop value. If the function is given a negative value, it will return 0 as an indicator that the value is invalid. Otherwise, the function will return the sum of every integer value from 0 to the stop value inclusively.
Function One
def sum_stop_int_1(stop: int) ->int:"""Add all of the numbers up to and including the provided stop value."""if stop <0:return0returnsum(range(stop +1))
Function Two
def sum_stop_int_2(stop: int) ->int:"""Calculate the sum of integers up to a given stop value."""if stop <0:return0return (stop * (stop +1)) //2
Difference between the Two Versions
Both functions take in an integer, stop, and return an integer. Inside both functions, there’s a conditional check to handle the case where the stop is less than 0. There is a difference in the return statements, the first function uses the sum and range functions to return the sum of range(stop + 1) which indicates the sequence from 0 up to the stop value. The second function directly computes the sum using the formula for the sum of an arithmetic series1: (n * (n + 1)) // 2, where n is the stop value.
Method
The timeit package is used to time these two functions. This package allows us to create and display the results of a doubling experiment conducted on both versions of the function. The outputs were used to compare the performance of these two functions.
Try It On Your Own
"""Tests the sum_stop_int function."""import timeit# Set the stop value for the testsstop_value =1000000# First Functiondef sum_stop_int_1(stop: int) ->int:"""All of the numbers up to and including the provided stop value."""if stop <0:return0returnsum(range(stop +1))# Second Functiondef sum_stop_int_2(stop: int) ->int:"""Calculate the sum of integers up to a given stop value."""if stop <0:return0return (stop * (stop +1)) //2# First Function Timingprint("First Experiment Timing:")execution_timesF1 = timeit.Timer(lambda: sum_stop_int_1(stop_value)).repeat(repeat=3, number=3)print("Execution times: ", ", ".join(f"{time:.6f}"for time in execution_timesF1))print("Average execution time: ", f"{sum(execution_timesF1) /len(execution_timesF1):.6f}")# Second Function Timingprint("Second Experiment Timing:")execution_timesF11 = timeit.Timer(lambda: sum_stop_int_2(stop_value)).repeat(repeat=3, number=3)print("Execution times: ", ", ".join(f"{time:.9f}"for time in execution_timesF11))print("Average execution time: ", f"{sum(execution_timesF11) /len(execution_timesF11):.9f}")
First Experiment Timing:
Execution times: 0.046417, 0.043658, 0.042217
Average execution time: 0.044097
Second Experiment Timing:
Execution times: 0.000003317, 0.000000791, 0.000000672
Average execution time: 0.000001593
Results
Data Outputs from Timing and Benchmarks
Function One
Result from running on MacOS 14.2.1
Function
Stop Value (int)
Run 1 Total Time (s)
Run 2 Total Time (s)
Run 3 Total Time (s)
Average Time (s)
sum_stop_int_1
1000000
0.027711
0.027467
0.027587
0.027588
sum_stop_int_1
2000000
0.054532
0.055076
0.055577
0.055062
sum_stop_int_1
4000000
0.111034
0.108958
0.108744
0.109579
sum_stop_int_1
8000000
0.22124
0.220475
0.219958
0.220558
sum_stop_int_1
16000000
0.439
0.440586
0.442671
0.440752
Function Two
Result from running on MacOS 14.2.1
Function
Stop Value (int)
Run 1 Total Time (s)
Run 2 Total Time (s)
Run 3 Total Time (s)
Average Time (s)
sum_stop_int_2
1000000
0.000002084
0.000000459
0.000000458
0.000001
sum_stop_int_2
2000000
0.000001042
0.000000625
0.000000708
0.000000792
sum_stop_int_2
4000000
0.000000833
0.000000625
0.000000625
0.000000694
sum_stop_int_2
8000000
0.000000791
0.000000625
0.000000625
0.00000068
sum_stop_int_2
16000000
0.000000791
0.000000625
0.000000583
0.000000666
Runtime Analysis
Function One
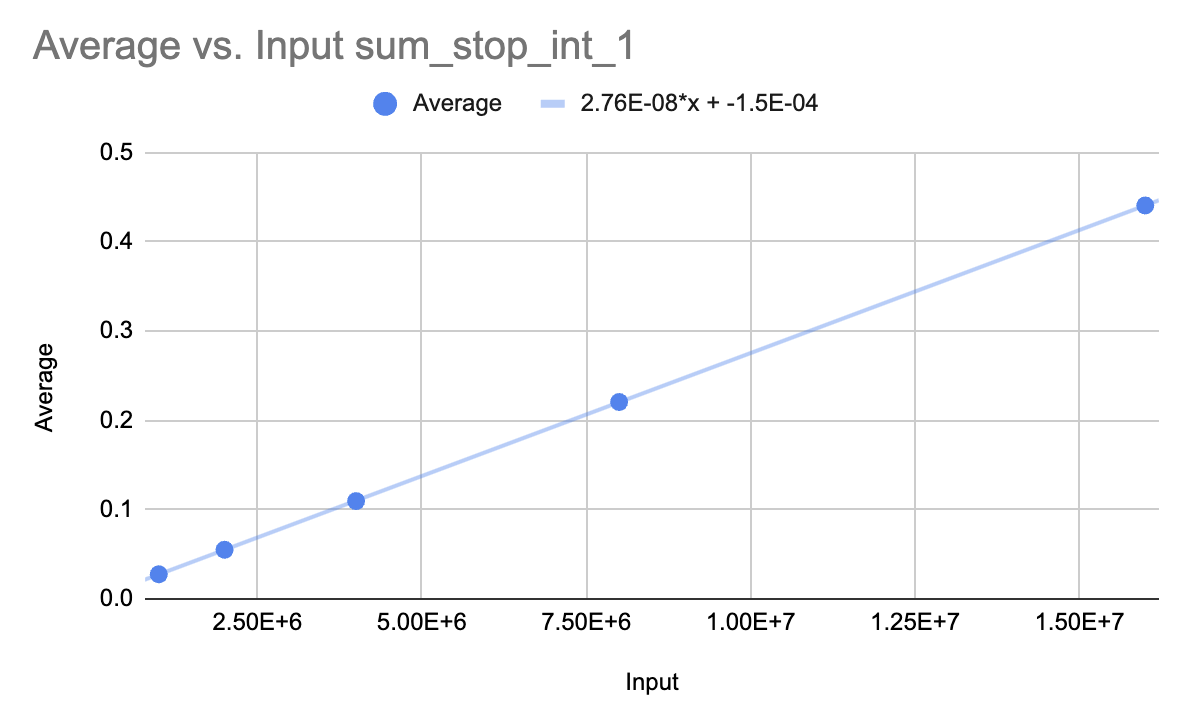
Average Execution Time as a Function of the Input Size
From the results of running the first version of sum_stop_int, it could be seen that the trend is a linear trendline. As the input of the function constantly increases, the average time of the runtime also constantly increases at the same rate. The running time gets longer as the input increases. The basic run time of the function is a lot slower compared to the second method. The time at the lowest input of stop = 1000000 was on average 0.027588 seconds compared to the second method was only 0.000001 seconds.
Function Two
Average Execution Time as a Function of the Input Size
From the results of running the second version of sum_stop_int, it could be seen that the trend is a sub-linear trendline. As the input increases, the time stays about the same and may even decrease based on outside factors. The basic run time of the function is also a lot faster compared to the first method. At the highest input the second method had an average run time of 0.000000666 seconds whereas the first method took almost half a second at 0.440752 on average to compute making it a lot worse than the second method.
Summary
Overall, the run time of the second method was a lot faster than the first. When strictly looking at input and output times we can see that at 1000000 the first function took 0.027587 seconds to achieve a result whereas the second only took 0.000001 seconds. In that instance the second method performed 99.99% better than the first. When looking at the largest input of our doubling experiment 16000000, the first method took 0.440752 seconds whereas the second only took 0.000000666 seconds. In this instance as well the second function is even closer to 100% better than the test run at the lower input.
Running Time Analysis
Function One
|def sum_stop_int1(stop: int) -> int:
| """All of the numbers up to and including the provided stop value."""
1| if stop < 0:
| return 0
2n| return sum(range(stop + 1))
Function one has a worst-case time complexity of \(O(n)\). The sum and range functions are performed sequentially and are not nested so instead of multiplying we only add the \(n\)’s together making \(2n\). When calculating big \(O\) the constants are dropped so we are left with \(n\), hence the worst-case time complexity is \(O(n)\). That means that this function has a linear order of growth and that time doubles with input size. The doubling ratio is close to \(2\). This can be found by dividing the result from stop = 2000000 by the result of stop = 1000000 which means that \(0.055062\) divided by \(0.027588\) is around \(2\). This experimentally confirms the first method has a linear order of growth.
Function Two
|def sum_stop_int(stop: int) -> int:
| """Calculate the sum of integers up to a given stop value."""
| # Check if stop value is less than 0
1| if stop < 0:
| return 0
| # Calculate the sum using the formula for the sum of an arithmetic series
1| return (stop * (stop + 1)) // 2
Function two has a worst-case time complexity of \(O(1)\). This means that it has a sublinear order of growth and is constant. There is no iteration present and this version only contains atomic operations with a cost of \(1\) hence there is a constant worst-case time complexity. The doubling ratio for method two is \(1\) which can be found by dividing the output of when the stop equals \(8000000\) by \(4000000\). This comes out to almost 1 because \(0.00000068\) seconds divided by \(0.000000694\) seconds equals \(.985\) which is a little less then \(1\). Sometimes the ratio is less than one which is really promising. This shows a constant or sub-linear order of growth.
Summary
Overall, function two has a better running time than function two because its worst-case time complexity does not grow at the speed that function one does. The performance of function one will take more time as the input size increases whereas function two will perform more or less the same regardless of the size of the input.
Conclusion
From the results of the runtime and running time of these two functions, we can conclude that the second method is faster. The doubling experiment shows that the second method can handle very large input sizes at the same rate of handling very small ones leading us to believe it has a better performance overall. The doubling experiment also shows that the first method grows linearly in run time as the input size increases which is a worse performance. Overall, we would recommend whenever you are doing integer computation to only use operations with a cost of \(1\) if at all possible.