Comparative analysis of sorting algorithms
Our Repository
Overview
This Algorithm All-Hands project had us create an application that performs benchmarking experiments on various sorting functions it’s given. It takes in the path to a python file, the name of a function within that file, and parameters for running a doubling experiment to benchmark the given function. A command for executing the program would look something like this poetry run allhands --starting-size 100 --number-doubles 5 --file ./allhands/sorting.py --function-name quick_sort.
After running the program, it prints out the data collected from the benchmarking such as the size and time of each run. It even produces a graph to visualize the doubling experiment more clearly.
In addition to creating this application, we used the finished version to benchmark and analyze various sorting functions to see which performed the best as well as compare those results to the time complexity of each algorithm.
Code
The execute_function function takes three parameters: file, function_name, and arg. The file parameter represents the path to the file containing Python code. The function_name parameter specifies the name of the function to be called from the code within the file, and the arg parameter is the argument to be passed to the specified function. This was the part of our system that allowed us to call specified functions from a desired file to test a sorting algorithm.
def execute_function(file, function_name, arg):
with open(file) as f:
exec(f.read(), globals())
return globals().get(function_name, lambda _: None)(arg)The run_sorting_algorithm function takes the name of a sorting algorithm and a list of integers as input. It profiles the sorting algorithm using the timeit package, which measures execution times. The function returns a tuple containing the minimum, maximum, and average execution times of the sorting algorithm.
The run_sorting_algorithm_experiment_campaign function orchestrates the entire experiment campaign. It takes the name of a sorting algorithm, a starting size for the lists to be sorted, and the number of times the list size should be doubled for experimentation. It iteratively generates random lists of increasing sizes, runs the sorting algorithm on each list using run_sorting_algorithm, and records the performance data in a table. Finally, it returns a list of lists, where each inner list represents a row of the data table containing the list size and corresponding performance metrics.
"""Conduct doubling experiments for provided algorithms that perform list sorting."""
from timeit import repeat
from typing import Any, List, Tuple
from allhands import generate
def run_sorting_algorithm(
algorithm: str, array: List[int]
) -> Tuple[str, str, str]:
"""Run a sorting algorithm and profile it with the timeit package."""
setup_code = f"from allhands.sorting import {algorithm}"
stmt = f"{algorithm}({array})"
times = repeat(setup=setup_code, stmt=stmt, repeat=3, number=10)
return (min(times)), max(times), (sum(times) / len(times))
def run_sorting_algorithm_experiment_campaign(
algorithm: str,
starting_size: int,
number_doubles: int,
) -> List[List[Any]]:
"""Run an entire sorting algorithm experiment campaign."""
data_table = []
while number_doubles > 0:
random_list = generate.generate_random_container(starting_size)
performance_data = run_sorting_algorithm(algorithm, random_list)
data_table_row = [
starting_size,
performance_data[0],
performance_data[1],
performance_data[2],
]
data_table.append(data_table_row)
number_doubles = number_doubles - 1
starting_size = starting_size * 2
return data_tableThe allhands function accepts parameters to customize its sorting algorithm evaluation process. starting_size defines the initial size of the data container, while number_doubles determines how many times the size should double during the experiment. The file parameter specifies the file path containing sorting algorithm functions, with a default value of “./allhands/ sorting.py”. Lastly, function_name indicates the sorting algorithm to evaluate, with “bubble_sort” as the default choice. These parameters offer users flexibility in configuring the experiment according to their specific needs and preferences. Additional, the allhands function also includes functionality to visualize the performance data. After conducting the experiments, the function generates a chart illustrating the execution times of the sorting algorithm across different input sizes. This chart is displayed directly in the CLI, providing users with a visual representation of the algorithm’s performance under varying data sizes.
def allhands(
starting_size: int = typer.Option(100),
number_doubles: int = typer.Option(5),
file: str = typer.Option("./allhands/sorting.py"),
function_name: str = typer.Option("bubble_sort"),
) -> None:
"""Conduct a doubling experiment to measure the performance of list sorting for various algorithms."""
console.print(
"\n🔬 Tool Support for Evaluating the Performance of Sorting Algorithms\n"
)
console.print(f"Starting size of the data container: {starting_size}\n")
console.print(f"Number of doubles to execute: {number_doubles}\n")
console.print("📈 Here are the results from running the experiment!\n")
all_results = []
for i in range(number_doubles):
size = starting_size * (2**i)
data_to_sort = generate.generate_random_container(size)
performance_data = benchmark.run_sorting_algorithm(
function_name, data_to_sort
)
max_time = max(performance_data)
max_times = [float(max_time)]
execute_function(file, function_name, data_to_sort)
all_results.append(max_times)
header = ["Input Size", function_name]
data = [
[starting_size * (2**i), results[0]]
for i, results in enumerate(all_results)
]
table = tabulate(
data, headers=header, tablefmt="fancy_grid", floatfmt=".5f"
)
console.print(table)
# plot
fig = make_subplots(rows=1, cols=1)
trace = go.Scatter(
x=[starting_size * (2**i) for i in range(number_doubles)],
y=[results[0] for results in all_results],
mode="lines+markers",
name=function_name,
)
fig.add_trace(trace)
fig.update_layout(
title=f"Evaluating the Performance of {function_name}",
xaxis_title="Input Size",
yaxis_title="Execution Time (s)",
showlegend=True,
margin=dict(l=20, r=20, t=60, b=20),
title_x=0.5,
)
fig.show()Analysis (includes charts and graphs)
The results indicate data trends that align with the expected worst case time complexities for each respective algorithm. When running the command poetry run all hands —starting-size 100 —number-doubles 5. The following plot was produced, graphically representing the growth rates of each algorithm.
🔬 Tool Support for Evaluating the Performance of Sorting Algorithms
Starting size of the data container: 100
Number of doubles to execute: 5
📈 Here are the results from running the experiment!
╒══════════════╤══════════╤═════════════╤═════════╤═════════╤═════════╤═════════════╤═════════╤═════════╤═════════╤══════════╕
│ Input Size │ bubble │ insertion │ merge │ quick │ tim │ selection │ heap │ shell │ radix │ bucket │
╞══════════════╪══════════╪═════════════╪═════════╪═════════╪═════════╪═════════════╪═════════╪═════════╪═════════╪══════════╡
│ 100 │ 0.00278 │ 0.00088 │ 0.00102 │ 0.00064 │ 0.00056 │ 0.00112 │ 0.00089 │ 0.00043 │ 0.00074 │ 0.00128 │
├──────────────┼──────────┼─────────────┼─────────┼─────────┼─────────┼─────────────┼─────────┼─────────┼─────────┼──────────┤
│ 200 │ 0.01441 │ 0.00342 │ 0.00202 │ 0.00134 │ 0.00131 │ 0.00409 │ 0.00188 │ 0.00106 │ 0.00170 │ 0.00403 │
├──────────────┼──────────┼─────────────┼─────────┼─────────┼─────────┼─────────────┼─────────┼─────────┼─────────┼──────────┤
│ 400 │ 0.03616 │ 0.01437 │ 0.00456 │ 0.00288 │ 0.00318 │ 0.01828 │ 0.00437 │ 0.00268 │ 0.00421 │ 0.01677 │
├──────────────┼──────────┼─────────────┼─────────┼─────────┼─────────┼─────────────┼─────────┼─────────┼─────────┼──────────┤
│ 800 │ 0.15153 │ 0.06530 │ 0.00998 │ 0.00629 │ 0.00789 │ 0.07552 │ 0.01023 │ 0.00703 │ 0.00878 │ 0.06457 │
├──────────────┼──────────┼─────────────┼─────────┼─────────┼─────────┼─────────────┼─────────┼─────────┼─────────┼──────────┤
│ 1600 │ 0.65154 │ 0.27892 │ 0.02223 │ 0.01282 │ 0.01750 │ 0.29391 │ 0.02249 │ 0.01782 │ 0.02071 │ 0.27288 │
╘══════════════╧══════════╧═════════════╧═════════╧═════════╧═════════╧═════════════╧═════════╧═════════╧═════════╧══════════╛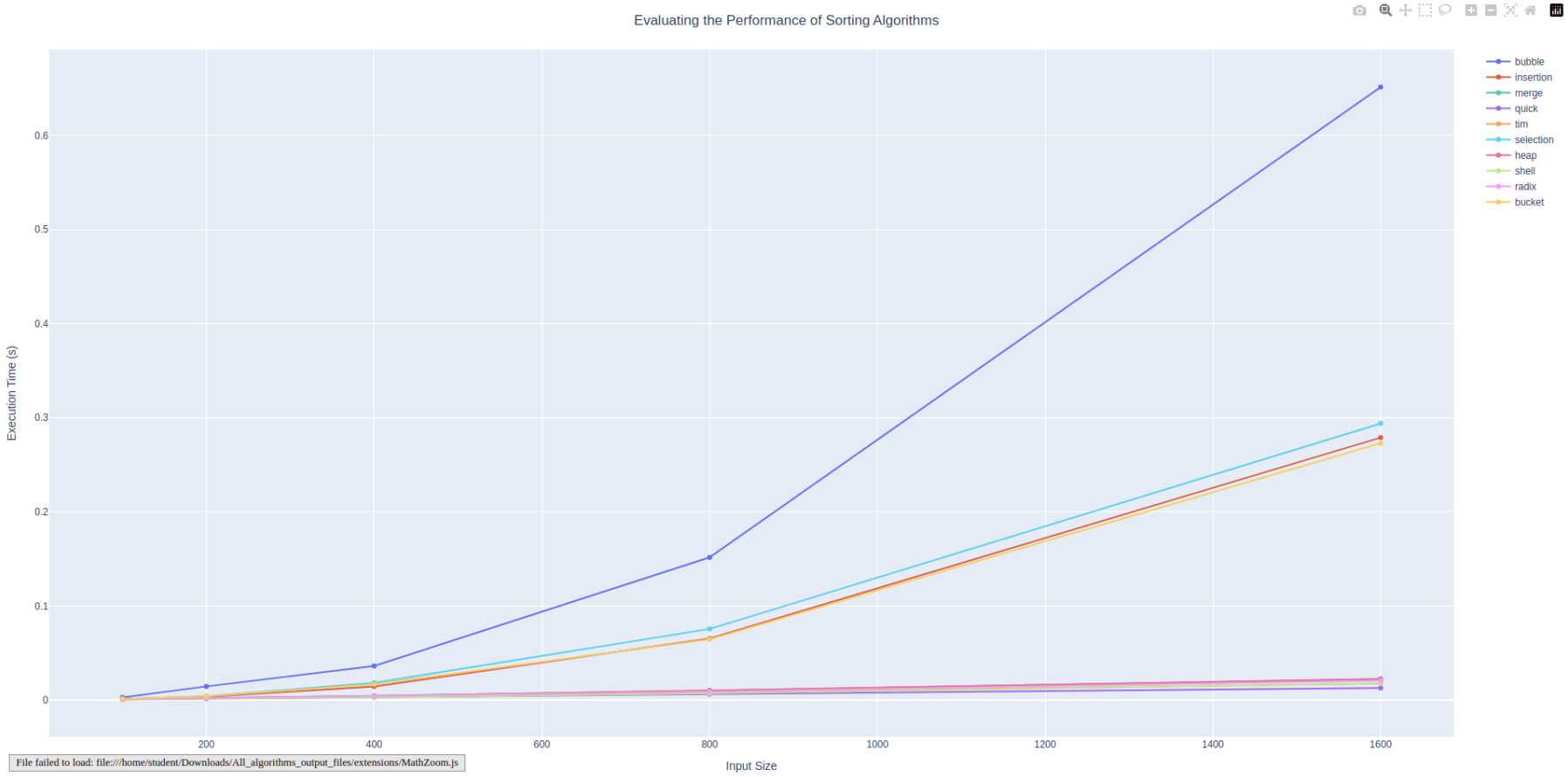
Bubble Sort
The expected worst case time complexity of bubble sort is O(\(n^2\)), which is confirmed by the results. The curve is parabolic, indicating a quadratic growth rate.
Insertion
The expected worst case time complexity of insertion sort is O(\(n^2\)), which is also confirmed via the results. This curve is also parabolic, however, the growth is not as large as bubble sort.
Merge Sort
The expected worst case time complexity of merge sort is O(nlogn). The graph indicates this as it is a near linear slope, but is not perfectly so. This is a growth rate improvement from the quadratic results above.
Quick Sort
The expected worst case time complexity of quick sort is O(\(n^2\)). The graph may be misleading because it appears to be a flatter curve, however, the data points indicate quadratic, just a much faster quadratic growth rate than the other algorithms.
Tim Sort
The expected worst case time complexity of tim sort is O(nlogn). The curve follows a similar growth rate to insertion sort, however, it performs slightly better as the maximum execution time is lower.
Selection
The expected worst case time complexity of selection sort is O(\(n^2\)). The curve maps this out as it follows a similar trajectory to the other parabolic algorithms, just at a faster overall execution time.
Heap Sort
The expected worst case time complexity of heap sort is O(nlogn). The heap sort curve follows this as it is a more efficient curve in terms of returns to scale than the parabolic ones, being closer to linear but not quite as quick.
Shell Sort
The expected worst case time complexity of shell sort is O(\(n^2\)). This has the same notes as quick sort, where the curve is quadratic, however, at such a small execution time for the given inputs that it is more shallow. The data points still follow the quadratic growth rate, though.
Radix Sort
The expected worst case time complexity of radix sort is O(nk). This curve appears similar to that of heap sort or other O(nlogn) algorithms, however, it displays a linear rate ate which the execution time grows with input. It is slightly more efficient than the linearithmic approaches.
Bucket Sort
The expected worst case time complexity of bucket sort is O(\(n^2\)). This curve seems to display a parabolic growth rate for input size and execution time, confirming the O(\(n^2\)) notation.
The best of the sorting algorithms in terms of long-term growth rate efficiency seems to be quick sort, while the worst performance was shown by bubble sort.
Conclusion
From the analysis of the plotted data, we can see that the most algorithms that have a quadratic growth rate, such as bubble, insertion, selection, and bucket sort have a significantly longer runtime as data scales up. On the other hand the more linearithmic algorithms such as radix, heap, tim, and merge produce faster runtimes. The only exceptions are both the quick sort and shell sort algorithms, these algorithms data points follow the quadratic growth rate but appear more shallow because of how small the execution times are comparatively to the other algorithms. Overall, we can conclude that the quick sort algorithm stands out as one of the most efficient sorting algorithms while the shell sort and tim sort algorithms are not far behind, you can see these three algorithms become more clearly faster as data scales up.